En este post vamos a emplear regresión lineal simple para cuantificar la influencia de cuatro variables demográficas y de estilo de vida sobre la presión arterial sistólica en población de Estados Unidos. Para ello hacemos uso de una base de datos llamada NHANES 2015-2016, cuyas siglas en inglés significan National Health and Nutrition Examination Survey.
Advertencia: En la ciencia de datos no basta únicamente con tener una base de datos y crear modelos, realizar análisis, inferencias, graficar y concluir algo que sea extrapolable a una población. Esto es, porque las bases de datos provienen de estudios que involucran metodologías propias del diseño experimental y, a su vez, tienen ciertas “características” estadísticas y supuestos que se deben cumplir si queremos que nuestras inferencias y conclusiones sean válidas. En el caso de la encuesta NHANES, se realiza lo que ellos denominan como “Complex Sample Survey” que incluye, entre otros elementos del muestreo, estratificación y conglomerados. Por lo que esto no es más que un ejemplo pedagógico.
Las variables de nuestra base de datos son las siguientes:
BPXSY1: Variable cuantitativa continua. Sistólica: Presión arterial sistólica, expresada en mm Hg.
SMQ020: Variable cualitativa dicotómica. Expresa si la persona ha fumado al menos 100 cigarrillos en toda su vida. 1: Sí, 0: No.
RIDAGEYR: Variable cuantitativa continua. Edad en años del participante en el momento del control, expresada en años. Las personas de 80 años o más se codifican con 80 años
RIAGENDR: Variable cualitativa dicotómica. Indica el género de la persona, 1: Hombre, 2: Mujer.
BMXBMI: Variable cuantitativa continua. Índice de masa corporal, expresado en kg/m**2
Lo que queremos hacer (o mejor dicho, tratarémos de hacer) es crear un modelo que nos relacione la presión arterial sistólica con las demás variables, de modo que vamos a seleccionar el modelo que mejor represente los cambios en la presión arterial sistólica que de ahora en adelante llamaremos PAS.
Primero, vamos a hablar un poco del origen de los datos:
El National Health and Nutrition Examination Survey (NHANES) es una encuesta integral diseñada y administrada por el Centro Nacional de Estadísticas de Salud (NCHS por sus siglas en inglés) que busca evaluar el estado de salud y nutrición de adultos y niños en los Estados Unidos. Combina información obtenida a través de entrevistas, así como exámenes físicos, el NCHS forma parte de los Centros para el Control y la Prevención de Enfermedades (CDC, por siglas en inglés) (Centers for Disease Control and Prevention, 2015).
La muestra se selecciona para representar a la población estadounidense, y los datos recopilados son utilizados, con fines investigativos, por universidades y agencias gubernamentales para establecer políticas de salud y programas de prevención. Además, NHANES ha proporcionado hallazgos significativos sobre la salud pública, como la prevalencia de diabetes no diagnosticada y tasas de obesidad (Centers for Disease Control and Prevention, 2015).
Si algunas de estas cosas que menciono son algo confusas, no hay ningún problema, lo que quiero que entiendas es que:
No es prudente inferir en una base de datos si no conocemos la forma en que se tomaron los datos, por ejemplo, esta es la del NHANES 2019-2020.
Es bastante útil conocer esta forma en que se tomaron los datos. Generalmente cada base de datos acompañado de un archivo que se llama “Documentación”, en él se explican todo lo que se hizo para conseguir estos datos y a su vez funciona como un manual de usuario de nuestra base de datos.
Un modelo de regresión puede servir (ser significativo) y esto es excelente, pero también puede no ser de utilidad para nuestros datos, y también está bien porque eso nos dice que debemos usar otro modelo más avanzado que se ajuste a ellos.
Análisis exploratorio
Lectura de la base de datos, como se observa a continuación, tanto la variable de edad como las del historial de tabaquismo se reportan como números, por lo que es conveniente realizar la conversión a factores para poder diferenciar cada categoría.
Luego de transformarlas a factores vamos a renombrar, por convenciencia, los valores a las etiquetas que representan, de modo que para la variable SMQ020, que indica si el individuo ha fumado más de 100 cigarrillos en su vida, pasará de los valores 1 y 2 a sí y no respectivamente. De igual modo la variable género (RIAGENDR) pasará de 1 y 2 a hombre y mujer. Esto nos sirve para que el modelo lo interprete como variables dummy.
library(forcats)dbx <- db %>%mutate(across(c(SMQ020, RIAGENDR), as_factor),SMQ020 =recode(SMQ020, "1"="si", "2"="no"),RIAGENDR =recode(RIAGENDR,"1"="hombre","2"="mujer"))summary(dbx)
BPXSY1 SMQ020 RIDAGEYR RIAGENDR BMXBMI
Min. : 82 si:2181 Min. :18.00 hombre:2586 Min. :14.50
1st Qu.:112 no:3158 1st Qu.:32.00 mujer :2753 1st Qu.:24.30
Median :122 Median :48.00 Median :28.30
Mean :125 Mean :48.02 Mean :29.35
3rd Qu.:134 3rd Qu.:63.00 3rd Qu.:33.00
Max. :236 Max. :80.00 Max. :64.60
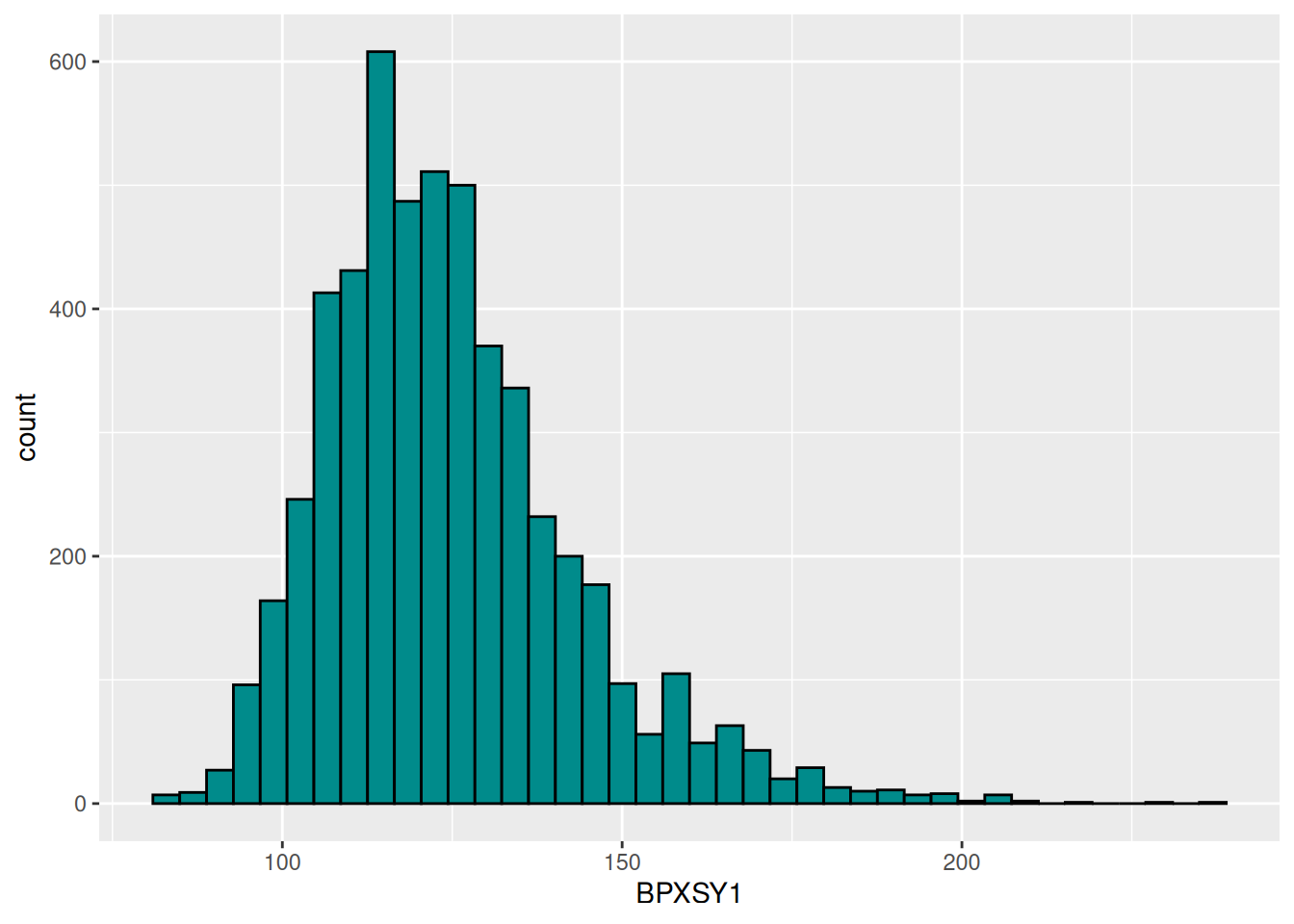
A continuación, se presenta la distribucón de los datos de presión arterial sistólica. Se observa un sesgo hacia la derecha que podría afectar más adelante el supuesto de normalidad. En este caso, la media se encuentra cerca de los 125 mmHg, estos niveles son superiores a una presión sistólica óptima (120 mmHg). Lo anterior puede significar una mayor ocurrencia de problemas relacionados con la presión arterial, tal y como sugiere Stamler, et al. (1993).
library(ggplot2)dbx %>%ggplot(aes(x = BPXSY1)) +geom_histogram(color ="black", fill ="Cyan4", bins =40)
Distribución de la Presión arterial sistólica
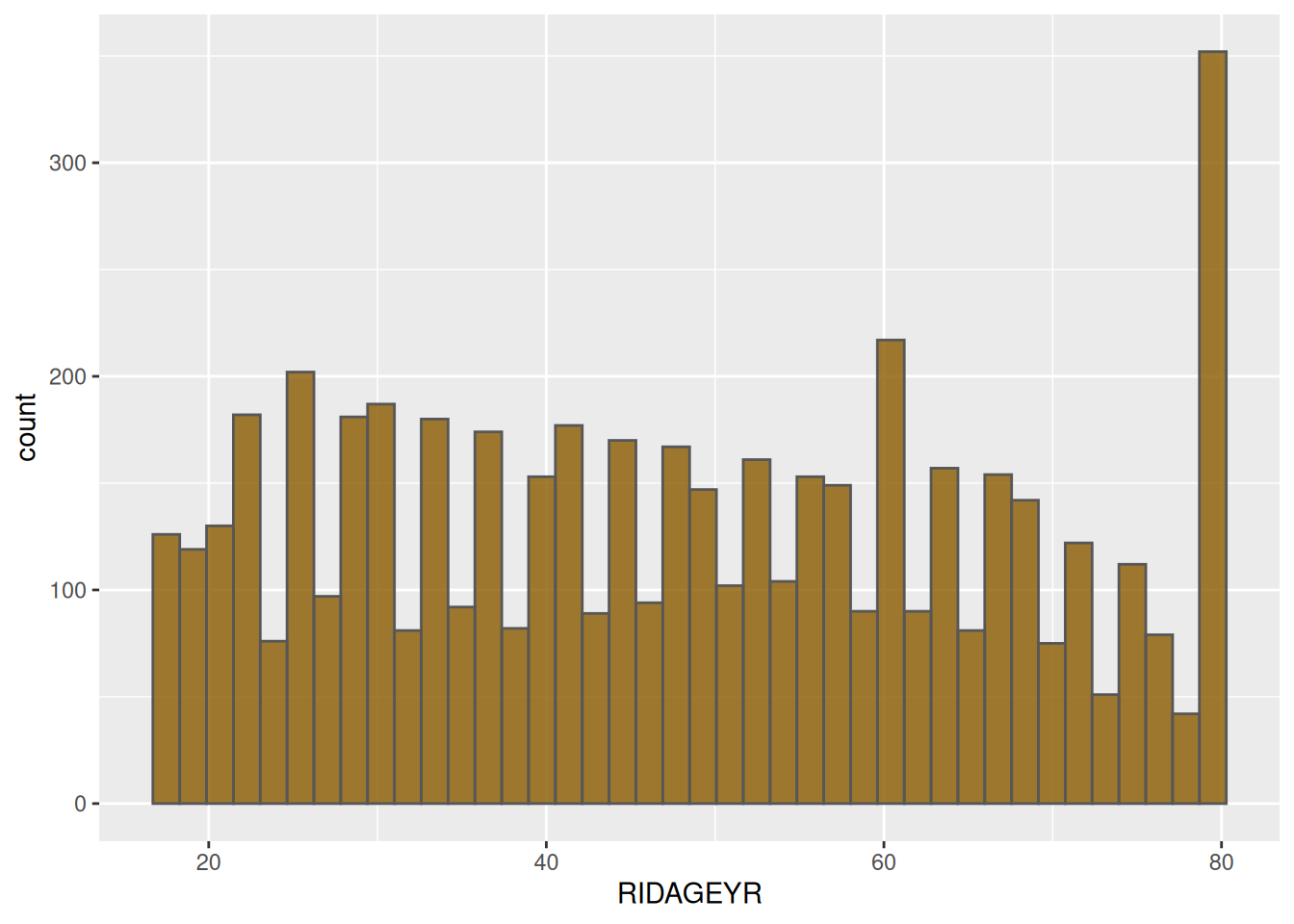
Para la distribución de edades no tenemos una distribución bien definida, algo que llama la atención es ese pico en los 80 años; sin embargo, la respuesta para esto es que aquellas personas con edades superiores a los 80 años, se les anota la edad de 80 años (CDC, 2015). Lo que causa sobrer-representatividad de la categoría.
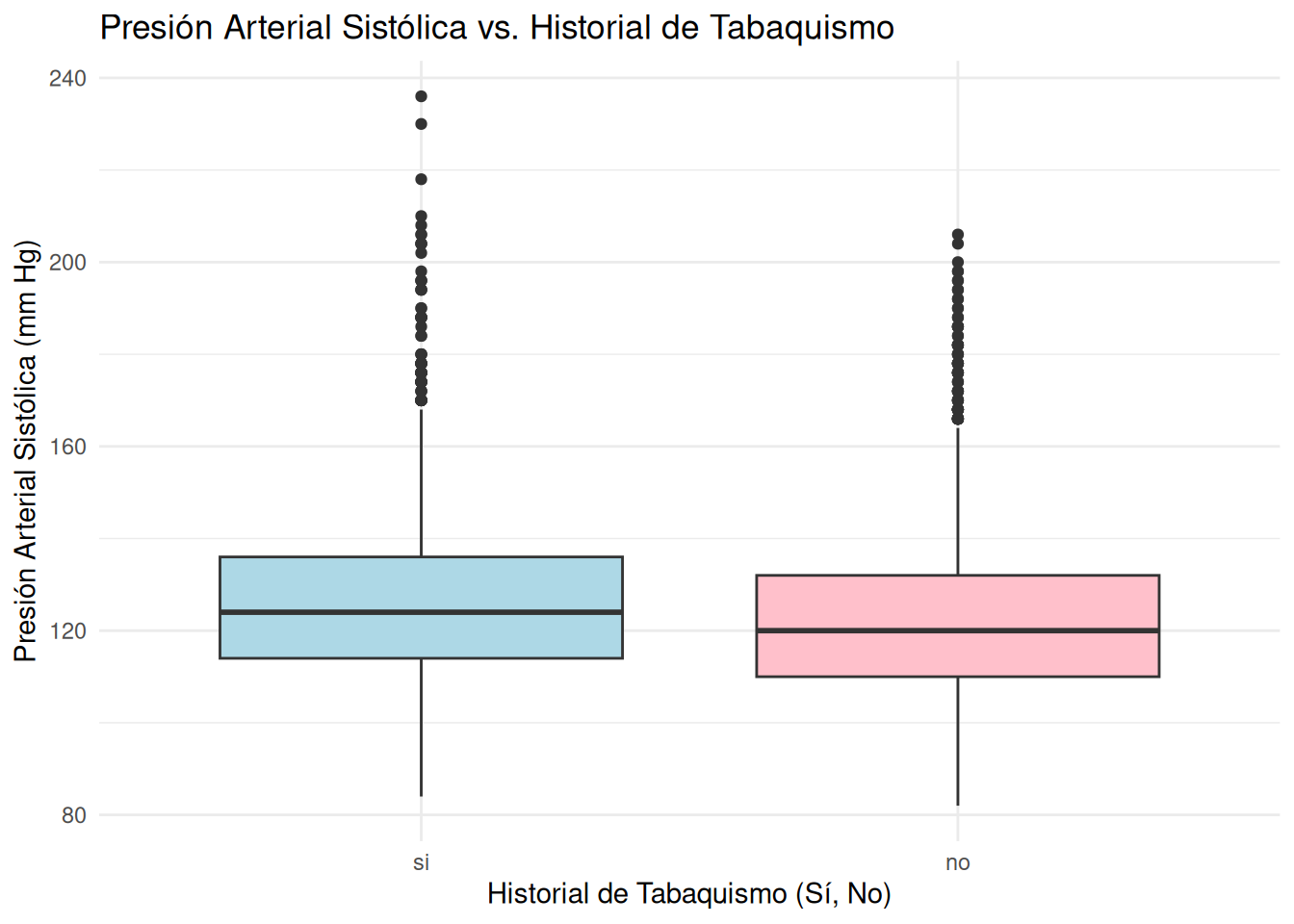
En la siguiente figura se sugiere que aquellas personas que han respondido positivamente a la pregunta del historial de tabaquismo, tienden a presentar una presión arterial superior con respecto a aquellas personas que no tienen este historial.
ggplot(dbx, aes(x = SMQ020, y = BPXSY1)) +geom_boxplot(fill =c("lightblue", "pink")) +labs(title ="Presión Arterial Sistólica vs. Historial de Tabaquismo",x ="Historial de Tabaquismo (Sí, No)",y ="Presión Arterial Sistólica (mm Hg)") +theme_minimal()
Presión arterial sistólica según el historial de tabaquismo
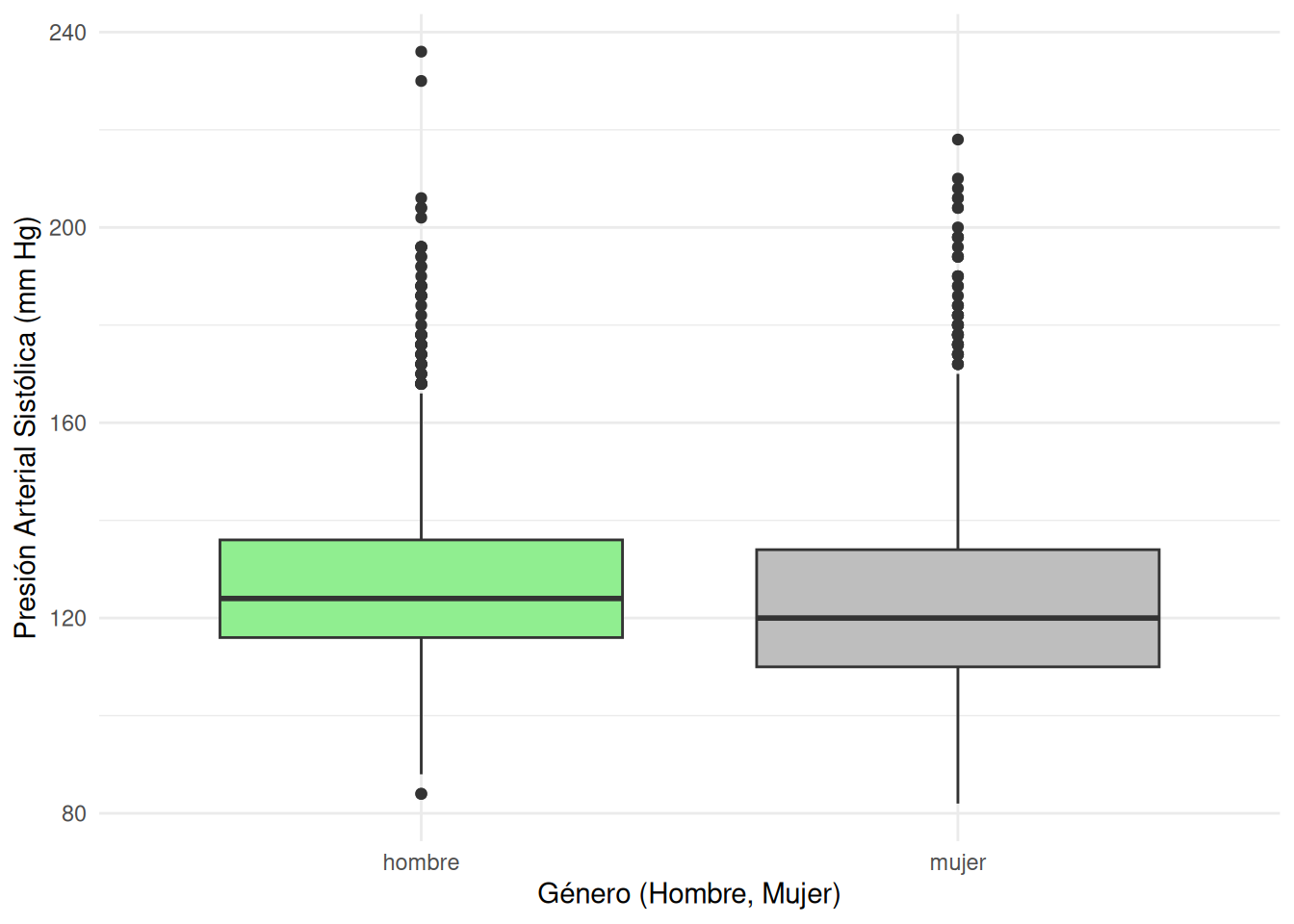
A simple vista (en el siguiente gráfico), los hombres presentan presiones sistólicas superiores a las de las mujeres, pero estas últimas tienen una mayor variabilidad (así como rango) en los niveles de presión arterial sistólica; sin embargo, esto último podría obedecer a factores que no estan representados en el gráfico.
Presión arterial sistólica según el género de la persona
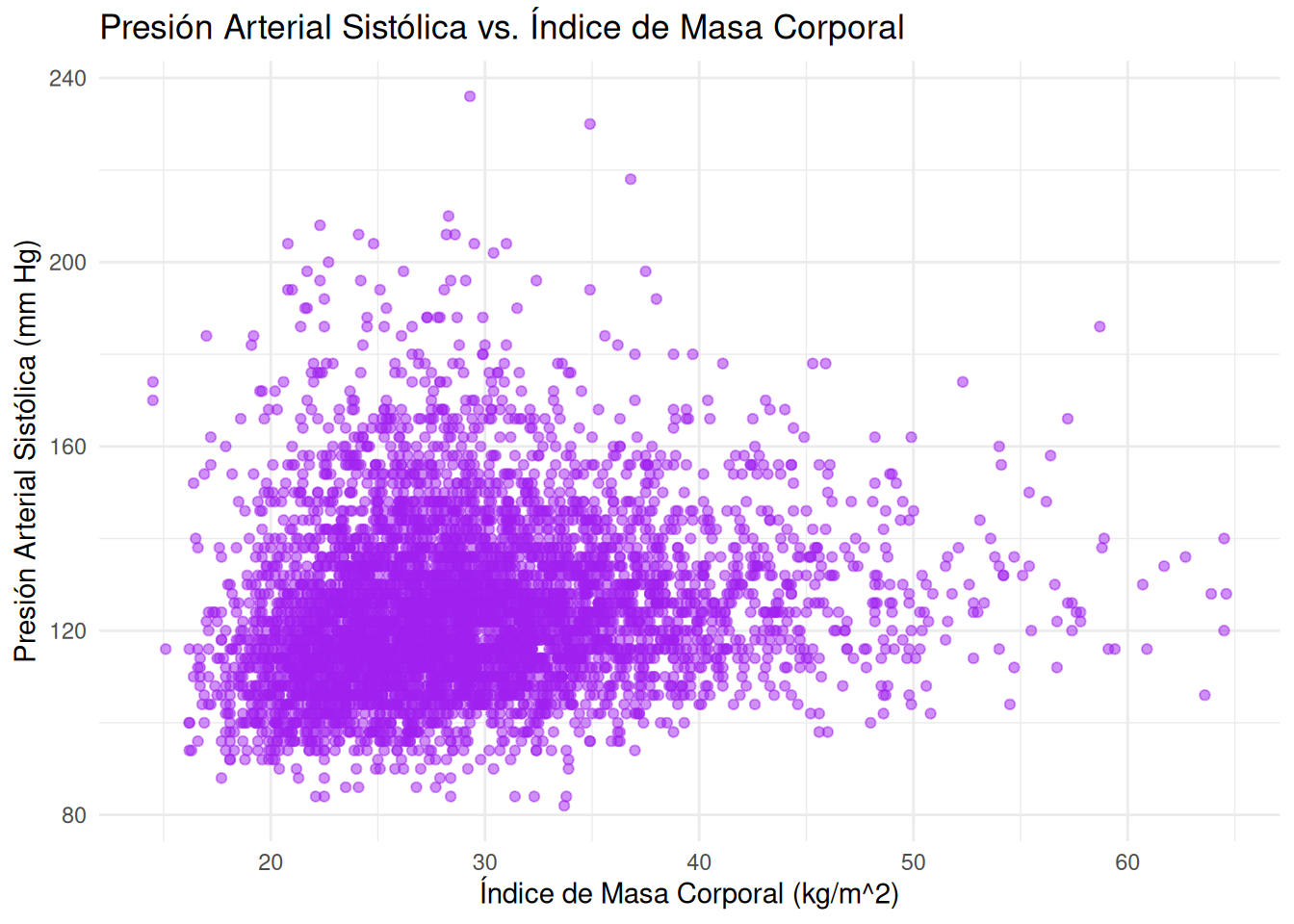
En el siguiente diagrama de dispersión se dibuja una aparente influencia del Índice de masa corporal sobre la presión arterial sistólica. Esto significa que la obesidad está relacionada con niveles altos de presión arterial sistólica, lo que podría ocasionar problemas de hipertensión en un futuro (He, et al., 2000)
ggplot(dbx, aes(x = BMXBMI, y = BPXSY1)) +geom_point(color ="purple", alpha =0.5) +labs(title ="Presión Arterial Sistólica vs. Índice de Masa Corporal",x ="Índice de Masa Corporal (kg/m^2)",y ="Presión Arterial Sistólica (mm Hg)") +theme_minimal()
Diagrama de dispersión de Presión arterial sistólica vs IMC
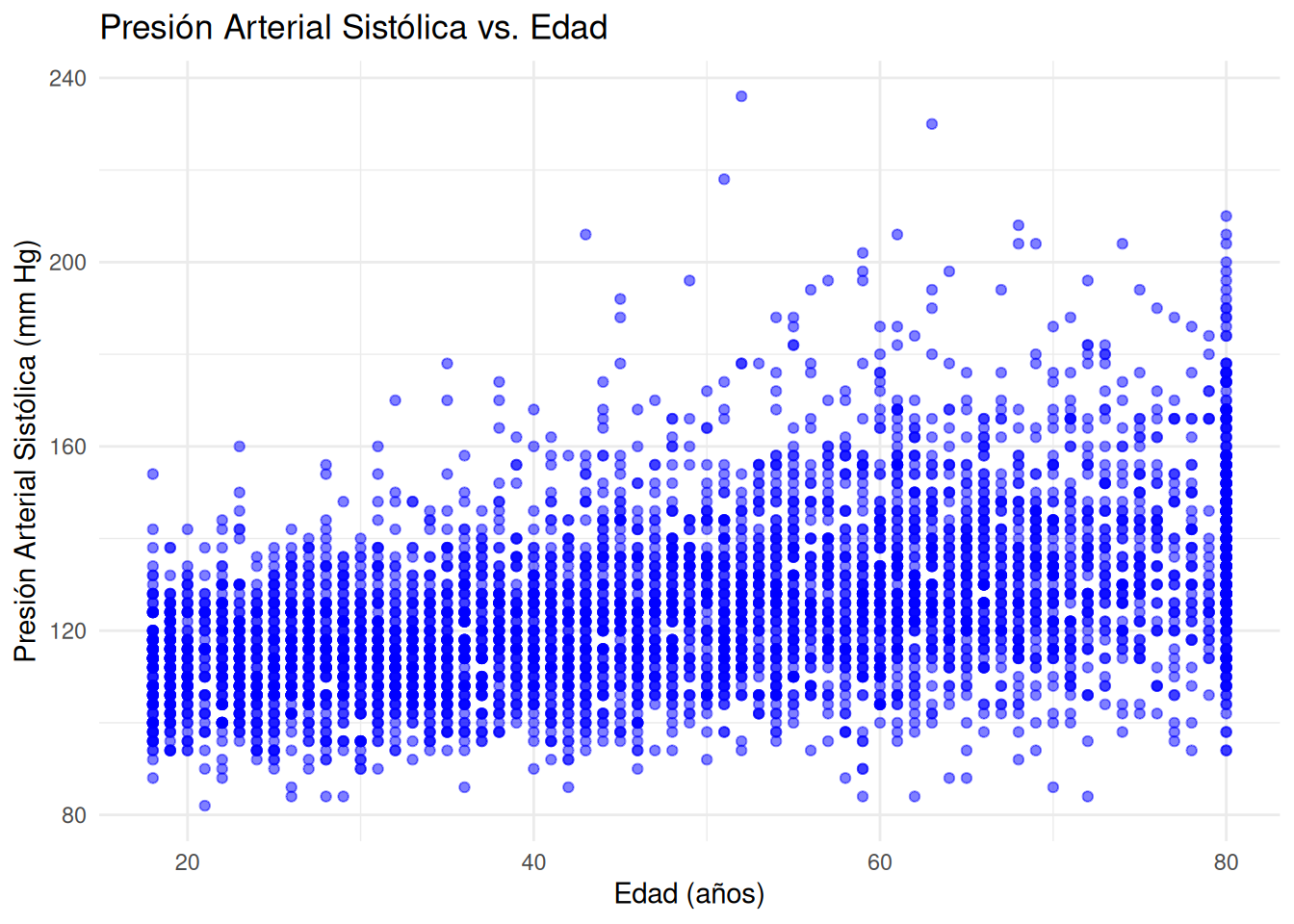
En la siguiente figura también se observa una aparente relación lineal positiva entre la edad y la presión arterial sistólica. Una posible explicación de este fenómeno podría ser la mayor prevalencia del uso de medicamentos, incluidos los antidepresivos, que tiende a aumentar con la edad (Landahl, et al., 1986).
Influencia de la edad en la presión arterial sistólica
Vaya! Al parecer el análisis exploratorio nos dió algunos indicios sobre las variables que se asocian más fuertemente con la PAS. Será que si creamos modelos de regresion lineal simple emparejando la PAS con cada una de las otras variables, podrémos sacar alguna conclusión? No lo sabrémos si no comenzamos a modelar.
Modelos de regresión simple
Como vimos en la sección anterior, todas las variables parecen tener influencia en la presión arterial sistólica, es preciso cuantificar la influencia de las variables cuantitativas sobre la misma. Para ello harémos uso del coeficiente de correlación de Pearson.
# Edad vs PAScor(dbx$RIDAGEYR, dbx$BPXSY1)
[1] 0.4708962
# IMC vs PAScor(dbx$BMXBMI, dbx$BPXSY1)
[1] 0.1350817
Si bien ambas presentan relación positiva con la PAS, la relación que tiene la edad es más fuerte que la del IMC, siendo 0.47 y 0.13 respectivamente. Esto podría sugerir, por ejemplo, que por cada año que se aumente, la presión arterial sistólica (PAS) se vería incrementada en 0.47 mmHg; no obstante, esto debe ser exáminado con modelos de regresión simple (Donde una variable puede explicar los cambios en la otra). En este caso, evidentemente, vamos a tomar a la presión arterial sistólica (PAS) como variable dependiente, y vamos a usar las otras cuatro (de forma separada) para explicar la primera. Y así escoger aquella que mejor explique esta variación.
Estimación e interpretación de los modelos
Para comenzar, vamos a crear un modelo de regresión simple para cada una de las variables explicativas:
tension_edad <-lm(BPXSY1 ~ RIDAGEYR, data = dbx)tension_fuma <-lm(BPXSY1 ~ SMQ020, data = dbx)tension_imc <-lm(BPXSY1 ~ BMXBMI, data = dbx)tension_genero <-lm(BPXSY1 ~ RIAGENDR, data = dbx)
Modelo de Edad
summary(tension_edad)
Call:
lm(formula = BPXSY1 ~ RIDAGEYR, data = dbx)
Residuals:
Min 1Q Median 3Q Max
-52.283 -10.650 -1.383 8.597 109.106
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 102.48363 0.61922 165.50 <2e-16 ***
RIDAGEYR 0.46944 0.01204 38.99 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 16.22 on 5337 degrees of freedom
Multiple R-squared: 0.2217, Adjusted R-squared: 0.2216
F-statistic: 1521 on 1 and 5337 DF, p-value: < 2.2e-16
La fórmula para el modelo de edad es \(\hat{PAS} = 102.5 + 0.47 \cdot Edad\), esto indica que por cada año más que tenga la persona, la presión arterial aumentará en 0.47 mmHg, también, si la persona tiene una edad de 0, la presión sistólica será de 102.5; sin embargo, esto carece de sentido puesto que los niveles difieren bastante de los de un bebé recién nacido (Hipertensión Arterial En Bebés: MedlinePlus Enciclopedia Médica, s. f.). Por otra parte, la edad es significativa para explicar la PAS (Lo que se confirma tanto con la prueba de T como con la de F).
Modelo de historial de tabaquismo
summary(tension_fuma)
Call:
lm(formula = BPXSY1 ~ SMQ020, data = dbx)
Residuals:
Min 1Q Median 3Q Max
-43.513 -13.308 -3.308 8.692 108.487
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 127.5131 0.3911 326.028 <2e-16 ***
SMQ020no -4.2046 0.5085 -8.268 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18.27 on 5337 degrees of freedom
Multiple R-squared: 0.01265, Adjusted R-squared: 0.01246
F-statistic: 68.36 on 1 and 5337 DF, p-value: < 2.2e-16
La fórmula de este modelo es \(\hat{PAS} = 127.5 - 4.20 \cdot Fuma\), esta variable tal y como la anterior es significativa. En este caso se hizo uso de una variable “dummy”, de modo que el nivel base es quellas personas que sí han fumado más de 100 cigarrillos en su vida, en tal caso, la presión arterial media sería de 127.5 mmHg, sin embargo, aquellas personas que no han fumado presentarían una disminución en la PAS de 4.2, lo que se traduce en una PAS de 123.3.
Modelo de IMC
summary(tension_imc)
Call:
lm(formula = BPXSY1 ~ BMXBMI, data = dbx)
Residuals:
Min 1Q Median 3Q Max
-44.567 -12.496 -2.830 9.064 110.993
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 114.62173 1.07397 106.73 <2e-16 ***
BMXBMI 0.35446 0.03559 9.96 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18.21 on 5337 degrees of freedom
Multiple R-squared: 0.01825, Adjusted R-squared: 0.01806
F-statistic: 99.19 on 1 and 5337 DF, p-value: < 2.2e-16
La fórmula en este caso es \(\hat{PAS} = 114.6 + 0.35 \cdot IMC\), también es significativa (o sea que es, aparentemente, válida para explicar los cambios en la PAS) e indica que por cada unidad que aumente el IMC, la PAS aumentará 0.35 mmHg, lo que coincide con lo mencionado anteriormente respecto a la influencia de la obesidad sobre la presión arterial sistólica.
Modelo de Género
summary(tension_genero)
Call:
lm(formula = BPXSY1 ~ RIAGENDR, data = dbx)
Residuals:
Min 1Q Median 3Q Max
-42.926 -12.926 -2.926 9.074 109.074
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 126.9258 0.3597 352.909 < 2e-16 ***
RIAGENDRmujer -3.6842 0.5009 -7.356 2.19e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18.29 on 5337 degrees of freedom
Multiple R-squared: 0.01004, Adjusted R-squared: 0.009851
F-statistic: 54.11 on 1 and 5337 DF, p-value: 2.186e-13
Finalmente, la fórmula de este modelo de regresión simple es \(\hat{PAS} = 126.9 - 3.7 \cdot Género\). También es significativa y sugiere que los hombres presentan (en promedio) una PAS mayor que las mujeres, siendo la de ellas (en promedio) 3.7 mmHg más baja.
Simplificando…
Todas las variables que vimos afectan, o tienen que ver con el cambio, en los niveles en la PAS de la siguiente forma:
Si fumas \(\rightarrow\) PAS \(\uparrow\)
Si envejeces \(\rightarrow\) PAS \(\uparrow\)
Si eres hombre \(\rightarrow\) PAS \(\uparrow\)
Si subes de peso \(\rightarrow\) PAS \(\uparrow\)
En resúmen, si cumples con todos los requisitos anteriores, eres este:
Elección del mejor modelo
Como no todo en la vida es color de rosa, no sólo basta con saber que los modelos son significativos. Desgraciadamente y afortunadamente la estadística es así de rigurosa, necesitamos verificar sobre la verificación de la verificación de la verificación y así de forma recursiva.
Ahora que tenemos indicios de la relación que estas variables tienen con la presión arterial sistólica, vamos a seleccionar aquel modelo que mejor se desempeñe en su explicación de la misma, para ello realizarémos algunas prueblas que nos van a ayudar a decantarnos por alguna de todas estas opciones. Estas pruebas son:
Desviación Media Absoluta
Error Cuadrático Medio
Error de Porcentaje Medio Absoluto
Estas tres se basan en los residuales, que en palabras simples indican la diferencia entre los valores observados y los valores predichos por el modelo, en tanto menor sea, mejor será el modelo. En colombiano sería algo como “¿Qué tanto nos descachamos?”.
n =length(dbx$BPXSY1)tension = dbx$BPXSY1e_e = tension_edad$residualsMAD_e =round(sum(abs(e_e)) / n, 2)MSE_e =round(sum(e_e^2) / n, 2)MAPE_e =round(sum(abs(e_e) / tension) / n*100, 2)
e_f = tension_fuma$residualsMAD_f =round(sum(abs(e_f)) / n, 2)MSE_f =round(sum(e_f^2) / n, 2)MAPE_f =round(sum(abs(e_f) / tension) / n*100, 2)
e_i = tension_imc$residualsMAD_i =round(sum(abs(e_i)) / n, 2)MSE_i =round(sum(e_i^2) / n, 2)MAPE_i =round(sum(abs(e_i) / tension) / n*100, 2)
e_g = tension_genero$residualsMAD_g =round(sum(abs(e_g)) / n, 2)MSE_g =round(sum(e_g^2) / n, 2)MAPE_g =round(sum(abs(e_g) / tension) / n*100, 2)
El R2 indica el porcentaje de variabilidad de la variable dependiente (PAS) que explica el modelo, mientras mayor sea, mejor será el modelo.
El AIC y el BIC tienen objetivos parecidos, pero emplean métodos algo distintos. El AIC se enfoca en evaluar la calidad relativa de los modelos estadísticos para un conjunto de datos específico y asiste en la elección de modelos que reduzcan la pérdida de información. En cambio, el BIC impone una penalización mayor por la complejidad del modelo, lo que puede llevar a la selección de modelos más sencillos (Kuha, 2004). Mientras menor sea su valor, mejor será el modelo.
Con el fin de hacer más sencilla la comparación de las métricas anteriormente obtenidas, vamos a construir la siguiente tabla:
En este caso, el modelo que mejor se comporta es el de la edad, pues es menor en todas las medidas, excepto en el R2 donde es mayor a los demás modelos. Por ello, el modelo seleccionado será el primero, este es:
\[\hat{PAS} = 102.5 + 0.47 \cdot Edad\]
Modelo
MAD
MSE
MAPE
\(R^2\)
AIC
BIC
Edad
12.24
262.87
9.75
22.17%
4.4904545^{4}
4.4924293^{4}
Fuma
13.97
333.5
11.12
1.26%
4.6175073^{4}
4.6194821^{4}
IMC
13.86
331.61
11.01
1.82%
4.6144705^{4}
4.6164453^{4}
Género
14
334.38
11.13
1%
4.618917^{4}
4.6208919^{4}
Análisis residual
Ahora que hemos elegido el modelo que mejor se desempeña, debemos corroborar que cumpla los supuestos necesarios. Para ello, realizaremos el análisis de los residuales.
Pruebas Gráficas
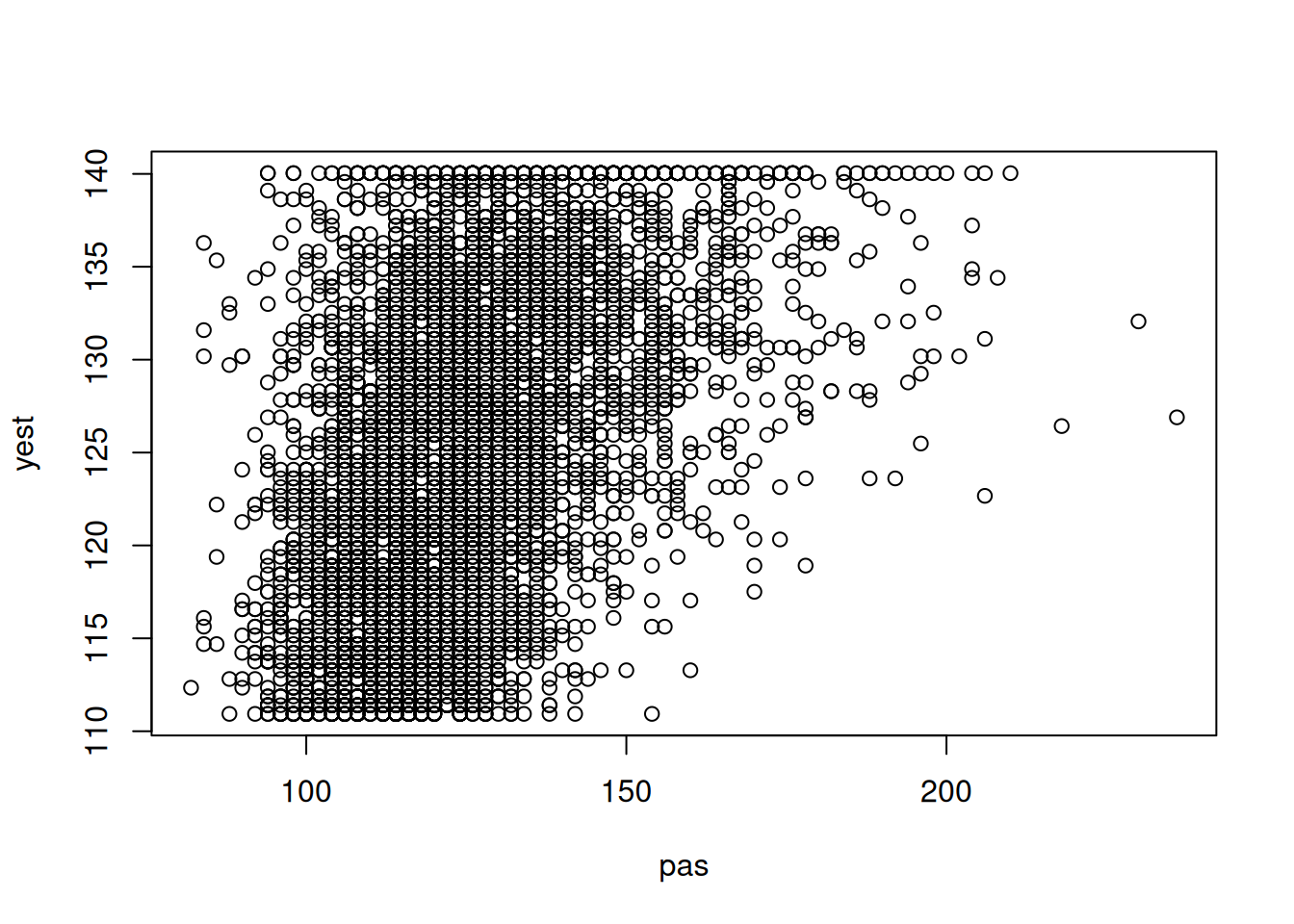
En el siguiente gráfico, vemos que existe un patrón en las observaciones, lo que podría indicar que el modelo predice parcialmente los modelos (una línea recta indicaría una estimación perfecta).
pas <- dbx$BPXSY1yest <- tension_edad$fitted.valuesplot(pas, yest)
Datos de PAS vs Estimados por el modelo
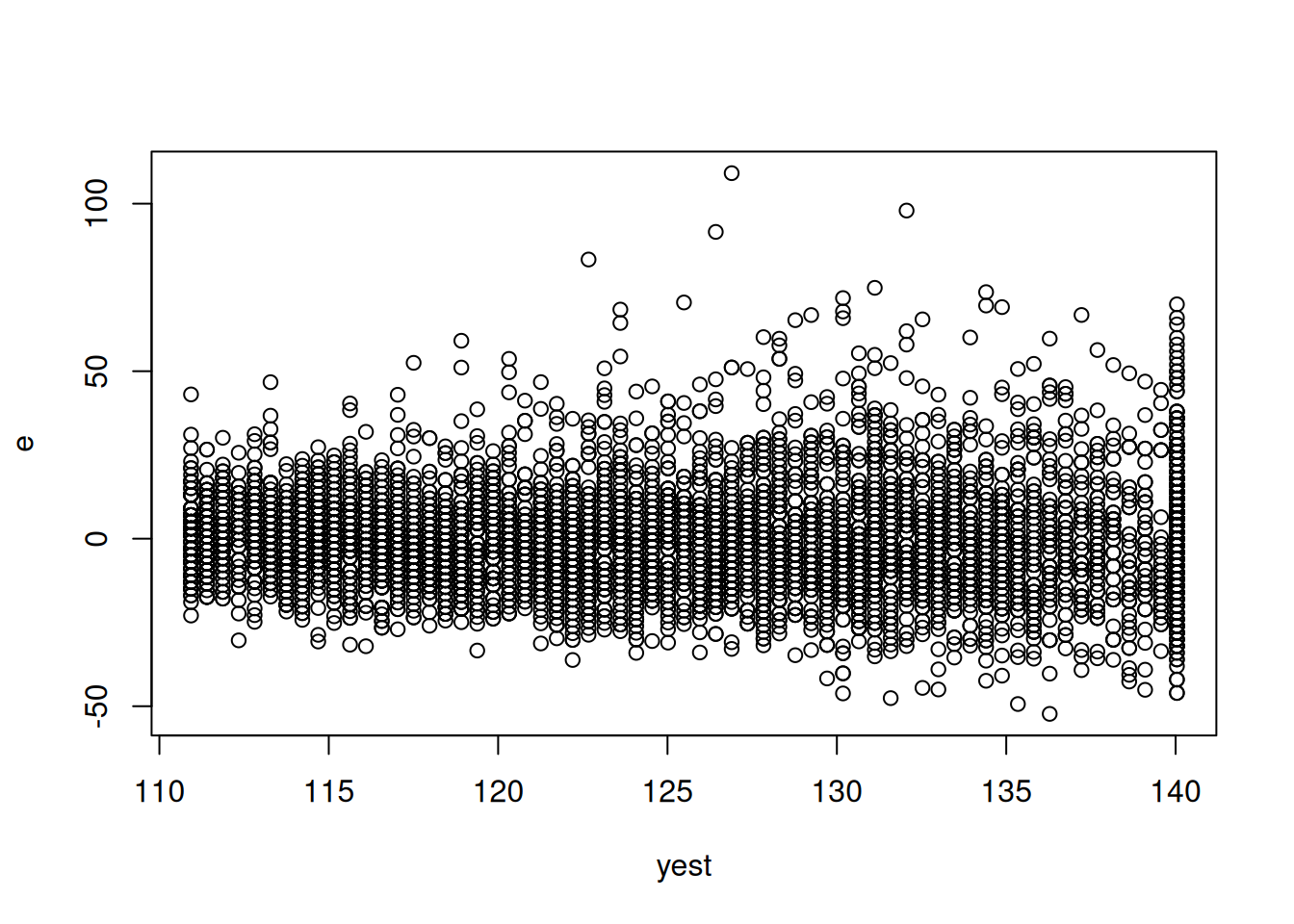
El modelo cumple, aparentemente, el supuesto de homocedasticidad, puesto que no se observa ningún patrón claro en la siguiente nube de puntos.
e <- tension_edad$residualsplot(yest, e)
Gráfico de residuales para supuesto de homocedasticidad
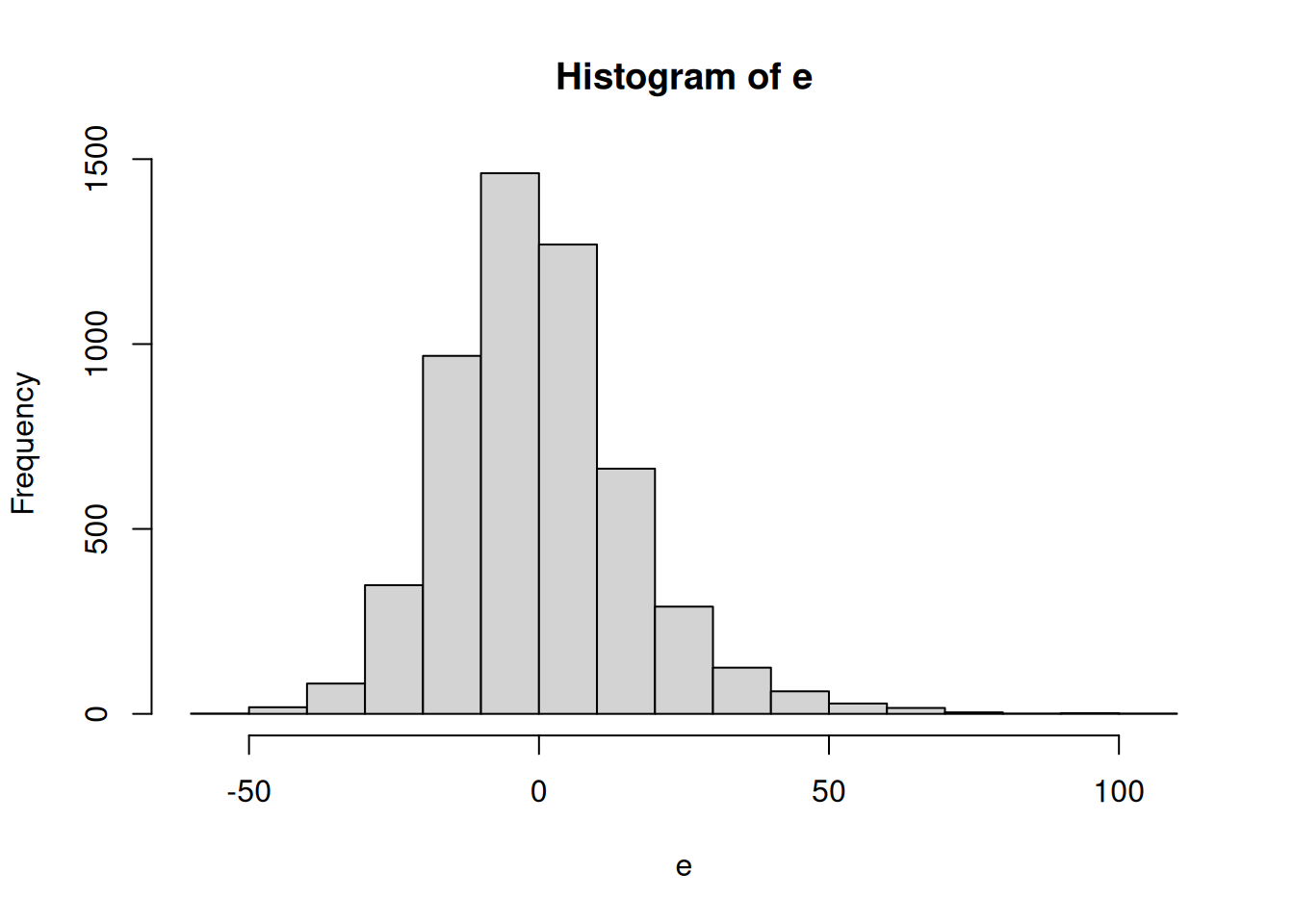
Los residuales siguen una forma de campana Gaussiana, esto nos da indicios de que cumple el supuesto de normalidad (y esto es muy importante).
hist(e)
Distribución de los residuales
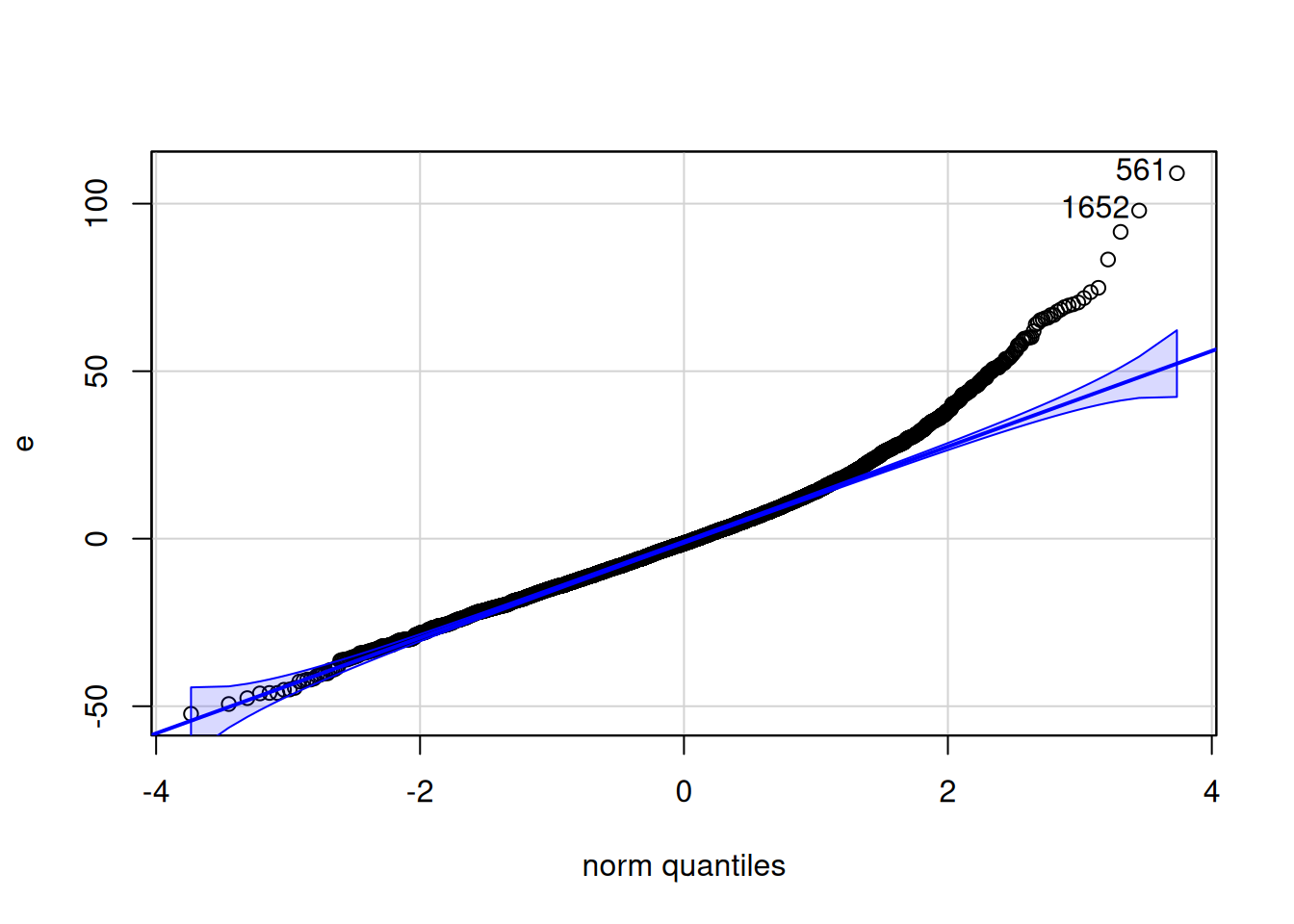
La figura a continuación nos sugiere una posible No normalidad, ocasionada por ese ligero desvío en la parte superior del gráfico (Los puntos deberían estar lo más alineados posible).
library(car)
Cargando paquete requerido: carData
Adjuntando el paquete: 'car'
The following object is masked from 'package:dplyr':
recode
qqPlot(e)
QQPlot para los residuales
[1] 561 1652
Pruebas analíticas de los supuestos
Si todo ha salido bien hasta el momento y no nos hemos preocupado, este es el momento en que debemos preocuparnos, la prueba de fuego, vamos a probar finura con estos modelos. Las pruebas analíticas es la manera “formal” de verificar los modelos, así las pruebas gráficas nos den bastante seguridad de nuestros modelos, siempre es necesario realizar esta re-verificación.
Dicho lo anterior, ahora vamos a verificarlo con pruebas estadísticas, en este caso suponemos que:
Normalidad
Para un nivel de significancia del 5%
\[H_0: \varepsilon_i \sim Normal\]
Cuando realizamos los test, con ninguno pasamos el supuesto de normalidad, por lo que debemos realizar alguna transformación que nos permita cumplir dicho supuesto. De lo contrario, ninguna de las pruebas de significancia del modelo será válida.
library(nortest)#No es posible realizar el test shapiro porque tenemos más de 5000 datos#shapiro.test(e)#> Error in shapiro.test(e) : sample size must be between 3 and 5000ad.test(e)
Anderson-Darling normality test
data: e
A = 30.492, p-value < 2.2e-16
lillie.test(e)
Lilliefors (Kolmogorov-Smirnov) normality test
data: e
D = 0.052686, p-value < 2.2e-16
Homocedasticidad
\[H_0: \sigma_{\varepsilon}^{2} = constante\]
Prueba de Breusch-Pagan
library(lmtest)bptest(tension_edad)
studentized Breusch-Pagan test
data: tension_edad
BP = 201.04, df = 1, p-value < 2.2e-16
\(pvalor \approx 0\). Se rechaza \(H_0\) y el supuesto de homocedasticidad no es válido
Prueba Goldfeld-Quandt
gqtest(tension_edad)
Goldfeld-Quandt test
data: tension_edad
GQ = 0.94905, df1 = 2668, df2 = 2667, p-value = 0.9115
alternative hypothesis: variance increases from segment 1 to 2
\(pvalor=0.94905\), \(\alpha < pvalor\), por lo tanto No se rechaza H0 y el supuesto es válido.
Aquí tenemos una contradicción en los tests de homocedasticidad
Transformación BoxCox
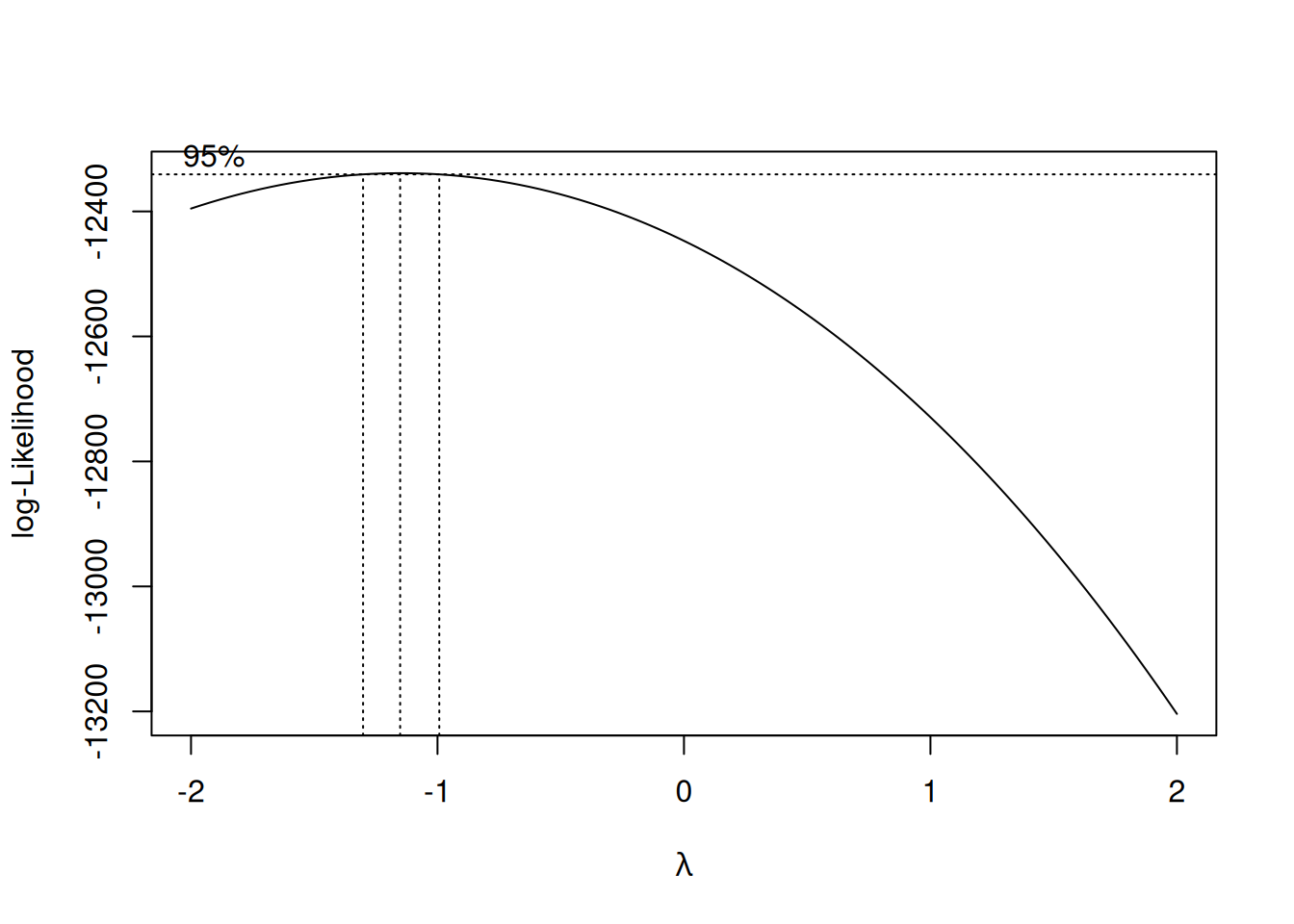
La Figura 11 nos insinúa que el valor de \(\lambda \approx -1\), en tal caso, la transformación que se debería usar es \(\dfrac{1}{PAS}\). De igual forma, es útil saber el valor puntual de \(\lambda\).
library(MASS)
Adjuntando el paquete: 'MASS'
The following object is masked from 'package:dplyr':
select
b =boxcox(lm(pas~1))
Gráfico de boxcox para determinación del valor de lambda
Con este valor, es preciso usar la transformación antes mencionada.
lambda=b$x[which.max(b$y)]lambda
[1] -1.151515
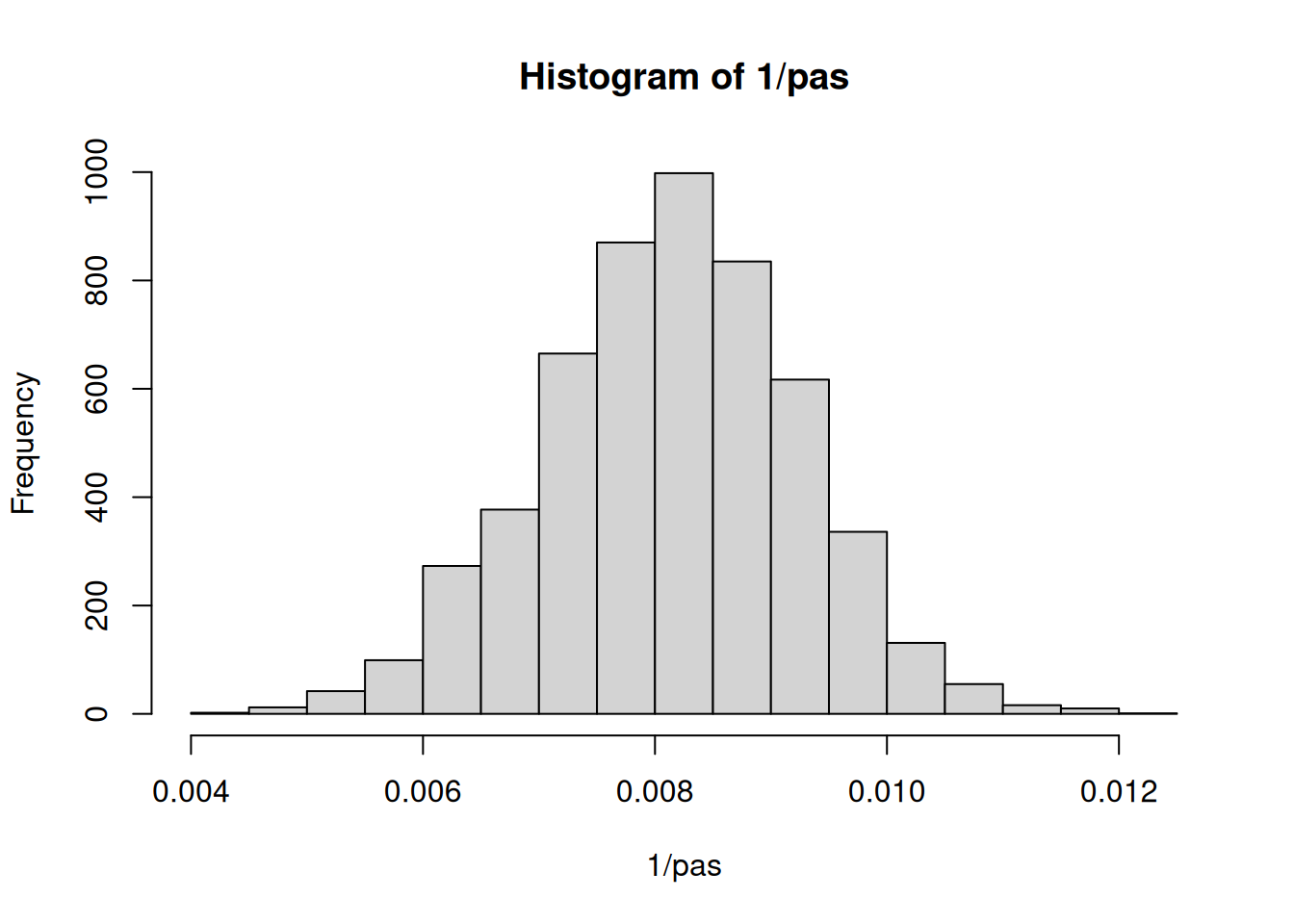
Luego de la transformación, vemos que el sesgo que presentaba hacia la derecha ha disminuido, sin embargo, la interpretabilidad también. Por lo que será un poco dificil cuantificar la influencia de la edad en la variabilidad de la presión arterial sistólica.
hist(1/pas)
Histograma de la variable PAS transformada
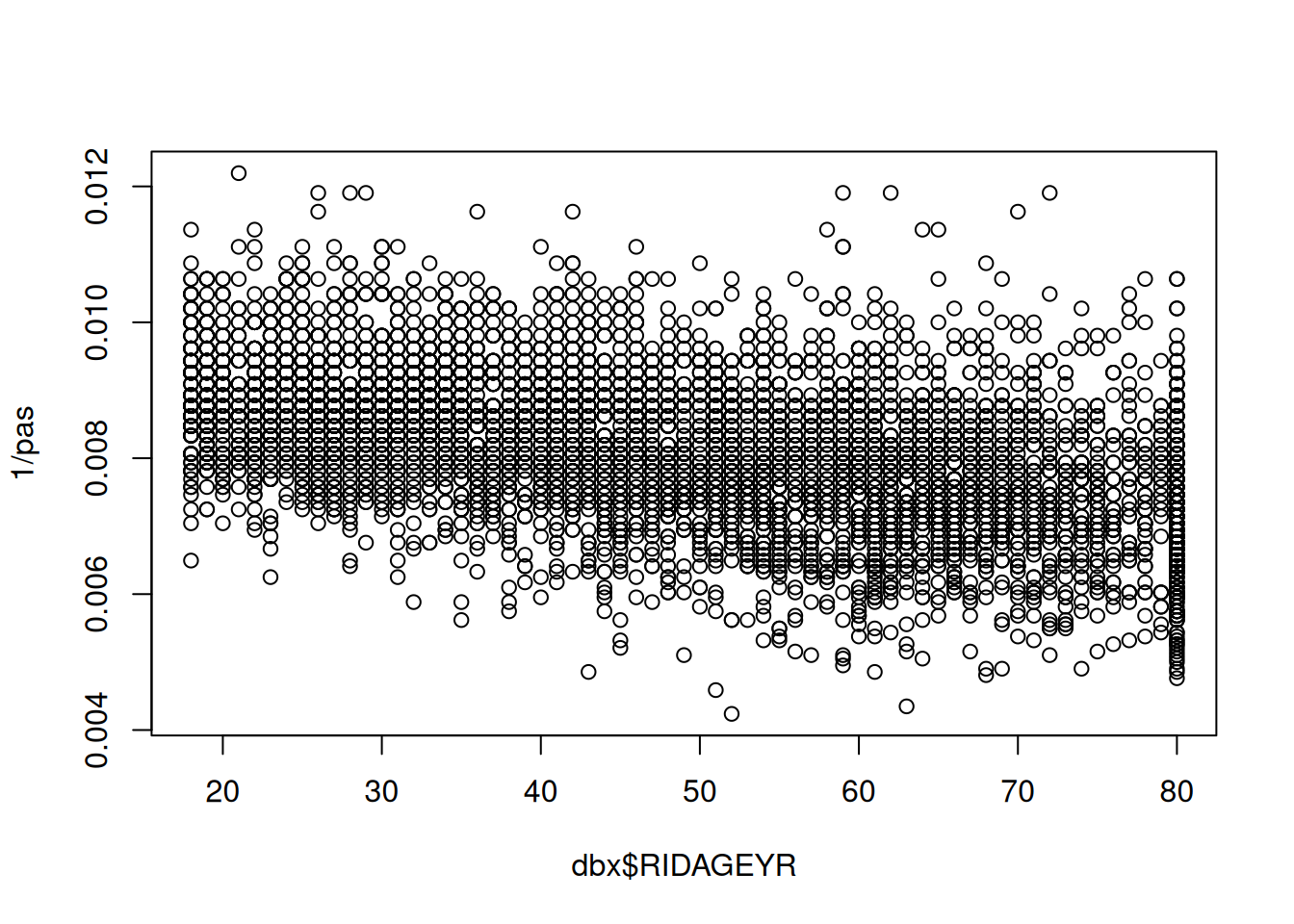
En la figura anterior, también se ve disminuido el incremento en la derecha, lo que hace parecer que los residuales cumplen el supuesto de homocedasticidad.
plot(dbx$RIDAGEYR, 1/pas)
Homocedasticidad con la variable PAS transformada
El modelo sigue siendo significativo, pero es poco interpretativo; sin embargo, este modelo sugiere una relación negativa entre la edad y el inverso de las medidas de presión arterial; por cada año de edad, 1/PAS disminuye en 0.00002852.
Call:
lm(formula = 1/pas ~ dbx$RIDAGEYR)
Residuals:
Min 1Q Median 3Q Max
-0.0038079 -0.0006388 -0.0000364 0.0006290 0.0044299
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.528e-03 3.758e-05 253.56 <2e-16 ***
dbx$RIDAGEYR -2.852e-05 7.306e-07 -39.04 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.0009841 on 5337 degrees of freedom
Multiple R-squared: 0.2221, Adjusted R-squared: 0.222
F-statistic: 1524 on 1 and 5337 DF, p-value: < 2.2e-16
En este caso, el modelo sigue sin cumplir el supuesto de normalidad
ad.test(mod_pas_edad$residuals)
Anderson-Darling normality test
data: mod_pas_edad$residuals
A = 3.0529, p-value = 1.166e-07
lillie.test(mod_pas_edad$residuals)
Lilliefors (Kolmogorov-Smirnov) normality test
data: mod_pas_edad$residuals
D = 0.021168, p-value = 1.1e-05
De igual manera que el modelo sin la transformación, la primera prueba no pasa el supuesto de homocedasticidad mientras que la segunda sí
bptest(mod_pas_edad)
studentized Breusch-Pagan test
data: mod_pas_edad
BP = 52.422, df = 1, p-value = 4.477e-13
gqtest(mod_pas_edad)
Goldfeld-Quandt test
data: mod_pas_edad
GQ = 0.96822, df1 = 2668, df2 = 2667, p-value = 0.7978
alternative hypothesis: variance increases from segment 1 to 2
Conclusión
En el contexto de los datos provenientes de la encuesta NHANES 2015-2016 sobre presión arterial sistólica y edad, las conclusiones del modelo de regresión simple indican que, a pesar de no cumplir con los supuestos de normalidad y homocedasticidad (incluso tras aplicar una transformación Box-Cox), es evidente que existe una relación entre estas variables. Por ello es importante considerar factores adicionales que pueden influir en la presión arterial. Dado el creciente problema de hipertensión en Estados Unidos, es crucial implementar planes preventivos basados en análisis estadísticos.
Además, dado que otros factores como el índice de masa corporal y el historial de tabaquismo también mostraron influencias relevantes en la presión arterial, es esencial considerar un enfoque holístico en las intervenciones de salud pública. Estas intervenciones deben centrarse no solo en la educación sobre estilos de vida saludables, sino también en programas específicos adaptados a las características demográficas y socioeconómicas identificadas en este estudio.
Por otro lado, dado que el modelo lineal simple puede no ser el más adecuado debido a las violaciones a sus supuestos básicos, se podría explorar otros enfoques estadísticos alternativos como Modelos lineales generalizados, regresiones Poisson o gamma.
En conclusión:
Comprobamos que existe una relación entre las PAS y las demás variables
No podemos asegurar nada porque no pasamos las pruebas
Tratamos de arreglar el modelo aplicando una transformación Box-Cox pero no funcionó para pasar las pruebas
Podríamos ver los datos u observaciones que afectan el modelo y nos lleva a que no sea significativo y ver si de alguna forma podemos imputar esos datos (aunque es delicado hacerlo si no se cuenta con la aprobación de un experto)
También podemos usar otra familia de modelos más compleja que refleje la naturaleza de los datos
Culpemos a los datos, el diseño muestral y veamos el mundo arder
Bibliografía
Centers for Disease Control and Prevention (CDC). National Center for Health Statistics (NCHS). National Health and Nutrition Examination Survey Data. Hyattsville, MD: U.S. Department of Health and Human Services, Centers for Disease Control and Prevention, 2015, https://wwwn.cdc.gov/Nchs/Nhanes/continuousnhanes/default.aspx?BeginYear=2015
He, Q., Ding, Z. Y., Fong, D. Y. T., & Karlberg, J. (2000). Blood pressure is associated with body mass index in both normal and obese children. Hypertension, 36(2), 165-170.
Hipertensión arterial en bebés: MedlinePlus enciclopedia médica. (s. f.). https://medlineplus.gov/spanish/ency/article/007329.htm
Kuha, J. (2004). AIC and BIC: Comparisons of assumptions and performance. Sociological methods & research, 33(2), 188-229.
Landahl, S. T. E. N., Bengtsson, C., Sigurdsson, J. A., Svanborg, A. L. V. A. R., & Svärdsudd, K. (1986). Age-related changes in blood pressure. Hypertension, 8(11), 1044-1049.
Stamler, J., Stamler, R., & Neaton, J. D. (1993). Blood pressure, systolic and diastolic, and cardiovascular risks: US population data. Archives of internal medicine, 153(5), 598-615.